Armeria는 어떻게 gRPC를 HTTP/1.1에서 사용할까?
gRPC는 기본적으로 HTTP/2 위에서 동작하는 프로토콜입니다. 그런데 Armeria가 가진 장점 중 하나로 gRPC를 HTTP/1.1 환경에서 gRPC를 사용할 수 있습니다. 비슷한 장점으로 HTTP/1.1 위에서 동작하는 Thrift를 HTTP/2 환경에서 서비스할 수 있습니다. Armeria는 어떻게 이런 유연한 통신 방식을 사용할 수 있을까요? 저 역시 최근 Armeria의 장점에 대해 정리해보다가 이걸 어떻게 구현했을까 궁금증이 생겨 공부하기 시작했습니다.
gRPC는 무엇인가
제가 궁금했던 부분을 정확히 공유하기 위해 간단하게 gRPC에 대해 설명하고 넘어가겠습니다. gRPC는 이름에서 알 수 있듯이 원격 프로시저 호출 프레임워크의 한 종류로 데이터를 주고 받을 때 프로토콜 버퍼를 사용해 이진 형식으로 직렬화합니다. gRPC에서는 요청과 응답의 형태에 따라 서비스를 4가지로 분류할 수 있습니다. 요청과 응답으로 단일 메시지를 주고받는 가장 간단한 형태, 응답이 스트림인 경우, 요청이 스트림인 경우, 요청과 응답이 모두 스트림인 경우로 총 4가지 입니다. gRPC의 요청, 응답 스트림을 HTTP로 어떻게 구현했을까요? HTTP/2와 HTTP/1.1에서 어떻게 다를까요? 제 궁금증은 여기서 출발했습니다.
gRPC는 HTTP/2에서 어떻게 동작할까?
먼저 기본적으로 HTTP/2에서 어떻게 동작하는지 알아봅시다. GitHub에 있는 gRPC 문서에
자세한 설명이 있습니다. 예를 들어 요청의 경우 Request-Headers *Length-Prefixed-Message EOS으로 표현합니다. ABNF syntax를
참고하여 해석하면 헤더, 길이가 앞에 붙은 메시지 여러 개, EOS로 구성됩니다. 그럼 이걸 HTTP/2에서 어떻게 구현했을까요? 문서를 읽어보면 생각보다 쉽습니다.
간단히 정리하면 RPC의 헤더는 HTTP의 헤더로 구현하고 Length-Prefixed-Message는 HTTP의 바디로 구현합니다. 이 때 스트리밍을 어떻게 구현했는지 알기 위해
HTTP/2에 대한 이해가 필요합니다. HTTP/2는 HTTP/1.1과 다르게 프레임
단위로 데이터를 주고 받습니다. 예를 들어 HTTP/1.1에서 요청을 보낼 때 요청 라인, 헤더, 바디로 이루어진 전문을 전송했다면, HTTP/2는 HEADERS 프레임,
DATA 프레임 등의 여러 타입의 프레임으로 쪼개서 전송합니다. 그래서 gRPC의 헤더는
HEADERS 프레임에 담아서 전송하고 length-prefixed-message는 DATA 프레임에 담아서 전송합니다. 이 때 요청이 스트림이여서 length-prefixed-message가
여러 개라면 DATA 프레임을 여러 번 전송합니다.
그럼 HTTP/1.1에서 어떻게 동작할까?
간단하게 생각했을 때 HTTP/1.1로 gRPC를 구현할 때 가장 어려운 부분은 어디일까요? 아마 스트리밍 처리일 것입니다. 단순히 헤더 + 바디로 이루어진 전문을 주고 받는다면 클라이언트가 보낼 스트림의 데이터를 모두 모아서 매우 큰 데이터를 서버에 전송해야 하니 메모리 부족 이슈 등의 문제가 발생할 것입니다. 다행히 HTTP/1.1에도 데이터를 쪼개서 전송할 방법이 존재합니다. Chunked Transfer Coding을 이용하면 바디의 데이터가 클 때 청크 단위로 쪼개서 전송할 수 있습니다. 하나의 청크는 첫 번째 줄에 사이즈와 두 번째 줄부터 청크 데이터로 이루어집니다. 청크 사이즈가 0인 경우 마지막 청크로 인식합니다. 또한 마지막 청크 다음 줄에 트레일러가 있어 추가적인 메타 정보를 전송할 수 있습니다. 청크의 구성이 gRPC의 length-prefixed-message와 거의 같습니다. 쉽게 예상하셨겠지만 gRPC의 헤더 정보는 똑같이 HTTP/1.1의 헤더에 넣고 length-prefixed-message는 청크에, gRPC의 트레일러는 청크 다음에 오는 HTTP/1.1의 트레일러로 구현하면 됩니다.
WireShark로 데이터 직접 확인하기
그럼 얼추 큰 그림을 이해했으니 직접 Armeria로 만든 예제에서 어떤 데이터가 오가는지 WireShark로 찍어보겠습니다. 우선 예제에 사용한 코드는 gRPC 공식 문서의 기본 튜토리얼 예제를 살짝 변형한 에코 서버입니다. 제 깃허브 armeria-grpc-practice에서 전체 코드를 확인하실 수 있습니다. 간단하게 protobuf 코드만 첨부하면 다음과 같습니다.
Message는 시퀀스 번호, 제목, 내용으로 이루어진 간단한 데이터 타입입니다. 서비스는 총 4개인데 각각 요청과 응답 스트리밍을 하냐 안하냐에 따라 달라집니다.
네 번째 서비스인 ManyToMany는 요청으로 보낸 메시지 스트림을 똑같이 스트림으로 응답합니다. 이걸 Armeria에서 HTTP/2, HTTP/1.1로 구현해 통신해보겠습니다.
총 3개의 메시지를 주고 받았습니다.
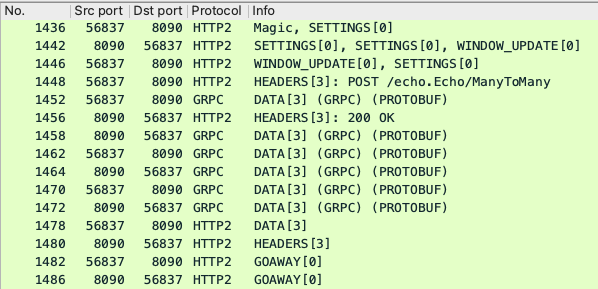
먼저 HTTP/2에서 주고 받은 프레임입니다. 8090은 서버, 56837은 클라이언트의 포트입니다. 먼저 처음 3개의 프레임(1436, 1442, 1446번)은 HTTP/2의
connection preface입니다. 참고로 WireShark는
가장 처음 클라이언트가 전송하는 PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n 문자열을 Magic으로 표시합니다.
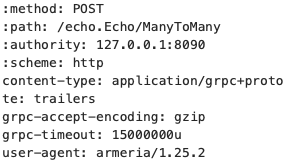
그 다음 1448번부터 본격적으로 데이터를 주고받기 시작합니다. 요청 헤더 중 콜론(:)이 붙은 헤더들이 모두 gRPC의 헤더 정보입니다. 헤더 전송 후 클라이언트는 첫 번째 DATA 프레임에 메시지를 담아 보냅니다. (1452번) 서버는 첫 번때 DATA 프레임을 받은 후 응답 헤더 프레임(1456번)과 에코 DATA 프레임(1458번)으로 응답합니다. 이후 클라이언트가 DATA 프레임을 전송할 때마다 에코로 응답합니다.
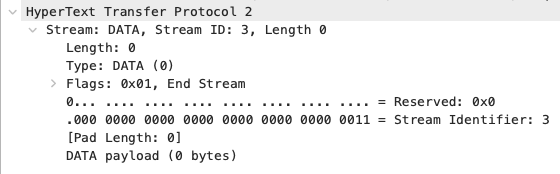
모든 데이터 전송을 마치면 클라이언트에서 END_STREAM 플래그가 켜진 DATA 프레임을 전송합니다. (1478번)
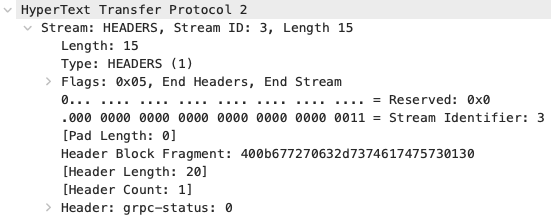
서버는 스트림이 끝났음을 인지하고 응답 트레일러를 HEADERS 프레임(1480번)에 담아 전송합니다. 사진의 grpc-status 필드를 gRPC는 통신 성공 여부를 마지막 트레일러에 담아 보내는 것을 확인할 수 있습니다. 마지막으로 GOAWAY 프레임을 주고받으며 HTTP/2 연결을 종료합니다.
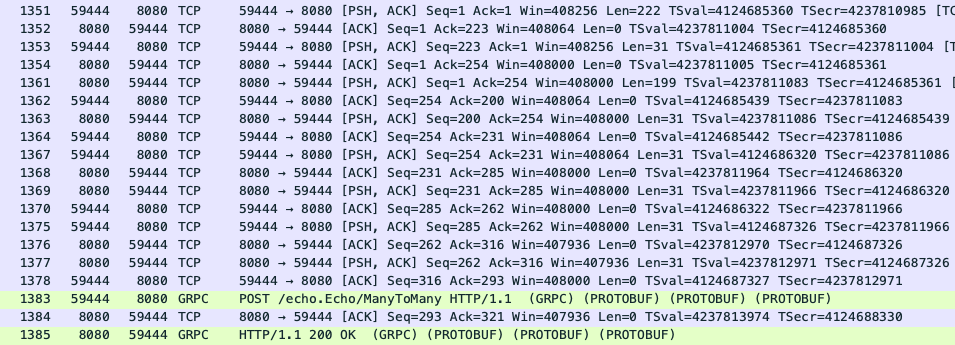
다음은 HTTP/1.1에서 어떻게 데이터를 주고받는지 확인해보겠습니다. WireShark는 주고받은 TCP 프레임을 알아서 조합해 완성된 HTTP 전문으로 보여줍니다. 청크로 쪼개서 데이터를 전송할 때 이 기능은 편리하게 전체 HTTP 전문을 확인할 수 있게 도와주지만 지금은 청크 단위로 데이터 통신 순서를 확인하기 위해 TCP 프레임까지 포함해 스크린샷을 남겼습니다.
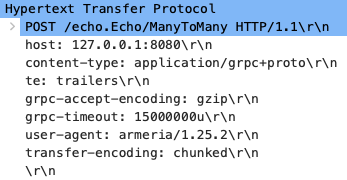
먼저 클라이언트는 서버에 요청 헤더를 보내는 것으로 시작합니다. (1351번) 헤더를 보면 앞에서 언급한 대로 transfer-encoding: chunked를 확인할 수
있습니다. 그 다음부터 데이터를 주고받는 순서는 HTTP/2와 매우 유사합니다. 클라이언트는 헤더를 전송한 이후 이어서 첫 번째 청크를 전송합니다. (1353번)
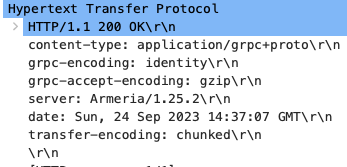
서버는 클라이언트의 첫 번째 청크를 받으면 응답 헤더를 전송합니다. (1361번) 마찬가지로 transfer-encoding: chunked 헤더를 확인할 수 있습니다. 응답
헤더를 보낸 뒤 이어서 첫 번째 에코 청크를 전송합니다. (1363번) 그 이후 클라이언트가 청크를 보낼 때마다 에코로 응답합니다.
모든 데이터 전송을 마치면 클라이언트는 끝났다는 것을 알리기 위해 마지막 청크로 0\r\n을 전송합니다. (1378번) 종료를 확인한 서버는 마찬가지로 0\r\n과
그 다음 줄에 트레일러로 grpc-status: 0을 담아 응답합니다. (1384번) 그리고 TCP 커넥션을 전송합니다.
정리하면 Armeria는 HTTP/1.1의 chunked transfer encoding을 활용해 HTTP/2와 유사하게 헤더와 바디 데이터를 주고받음을 알 수 있습니다. 그럼 마지막으로 코드는 어떻게 구현했을까요?
코드 들여다보기
이 글에서는 HTTP/1.1 cleartext 환경에서 작동하는 서버 코드 중 디코딩 과정 위주로 설명하겠습니다. Armeria는 HTTP 클라이언트로서의 기능도 뛰어나지만 기본적으로 서비스 프레임워크이니 서버 코드를 보겠습니다. Armeria의 코드를 이해하기 위해선 기본적으로 Netty에 대한 지식이 필요합니다. 개인적으로 Netty in Action 정도만 읽었는데 그 정도면 이해하는데 충분하다고 봅니다. (저도 모든 코드를 빠삭하게 이해하고 있진 않고 큰 그림을 이해하는 정도입니다.)
우선 클라이언트가 보낸 요청이 어떤 ChannelHandler를 거쳐서 사용자가
작성한 서비스 코드까지 도달하는지 따라가보겠습니다. 우선 Armeria의 Server#start() 흐름을 따라가면 ChannelFuture doStart(ServerPort port)
메소드를 실행합니다. 여기서 Netty의 bootstrap 과정을 확인할 수 있습니다. 코드를 따라가면 HttpServerPipelineConfigurator를 사용하는데 ChannelInitializer
구현체로 처음에 여러 ChannelHandler를 파이프라인에 설치합니다. 더 따라가면 Http2PrefaceOrHttpHandler와 HttpServerHandler 2개의 채널
핸들러를 파이프라인에 추가합니다. Netty의 유연한 통신 방식 설정 중 하나는 동적으로 들어온 데이터에 따라 채널 핸들러를 교체할 수 있다는 점입니다.
Http2PrefaceOrHttpHandler는 HTTP/2의 connection preface를 확인하면 HTTP/2 디코딩에 필요한 채널 핸들러를 설치하고 그렇지 않은 경우 HTTP/1.1에
필요한 채널 핸들러를 설치한 뒤 자신을 제거합니다. HTTP/1.1 요청을 받으면 Netty의 HttpServerCodec, HttpServerUpgradeHandler, Http1RequestDecoder를
설치합니다. 그럼 최종적으로 채널 핸들러는 순서대로 HttpServerCodec, HttpServerUpgradeHandler, Http1RequestDecoder, HttpServerHandler가
됩니다. (앞 뒤로 몇 개 더 있지만 생략했습니다.)
그럼 클라이언트가 헤더를 먼저 보냈을 때 어떤 일이 일어나는지 보겠습니다. 우선 Netty의 HttpServerCodec(엄밀히는 HttpRequestDecoder)이 알아서
이진 데이터를 파싱해줍니다. HttpServerUpgradeHandler는 HTTP/1.1에서 HTTP/2나 WebSocket으로 업그레이드할 때 사용하기 때문에 넘어갑니다. 그 다음
Http1RequestDecoder에서 Netty의 파싱 결과를 변환해 Armeria의 HttpRequest로 만듭니다. 이 과정이 중요한데 먼저 받은 헤더에 있는 path와 method 등을
이용해 어떤 서비스를 실행할지 찾는 라우팅 과정을 거칩니다. Spring MVC의 dispatcher servlet과 유사합니다. 라우팅 결과를 담아 HttpRequest 구현체인
StreamingDecodedHttpRequest 인스턴스를 생성합니다. 이 때 요청 스트림이 아직 끝나지 않았기 때문에 진행 중인 요청을 내부 필드에 저장합니다. 그리고
다음 핸들러인 HttpServerHandler에 인스턴스를 넘깁니다.
HttpServerHandler는 받은 StreamingDecodedHttpRequest 내부에 들어있는 라우팅 결과를 보고 서비스를 불러옵니다. 그럼 사용자가 작성한 코드를
담고 있는 FramedGrpcService 인스턴스를 얻습니다. 이제 서비스 인스턴스에 컨텍스트와 함께 StreamingDecodedHttpRequest를 넣습니다. 코드를 따라가면
FramedGrpcService#doPost() 메소드를 실행하는데 여기서 HttpRequest 스트림을 HttpResponse 스트림이 구독합니다. 이 과정에서 나중에 받을
HTTP 바디 청크의 이진 데이터를 프로토콜 버퍼로 디코딩하는 과정이 들어있습니다.
이제 헤더 처리가 끝나고 본격적으로 데이터를 담은 청크가 도착한 경우를 보겠습니다. 똑같이 Netty의 HttpServerCodec을 거쳐 파싱 후 Http1RequestDecoder에
도착합니다. 이전에 헤더를 처리할 때 생성한 StreamingDecodedHttpRequest 인스턴스의 참조를 내부 필드에 저장했는데요. 파싱 결과를 Armeria의 HttpData로
변환하고 StreamingDecodedHttpRequest#write() 메소드의 인자로 넣어 HttpRequest 스트림에 데이터를 보내줍니다. 그럼 스트림을 타고 사용자의 코드를
거친 후 헤더 처리 때 연결했던 HttpResponse 스트림으로 도달합니다. 마지막 청크인 경우 Netty는 LastHttpContent 타입으로 파싱합니다. Armeria는
이걸 확인하고 트레일러가 있으면 마저 요청 스트림에 써준 뒤 스트림을 닫습니다.
여기까지 HTTP/1.1 환경에서 서버가 요청을 디코딩하는 과정을 훑어봤습니다. 서버가 응답할 때 인코딩은 어떤 과정을 거치는지, 클라이언트는 어떻게 구현되어있는지 알아야 할 것이 많지만 비슷하게 Netty의 채널 핸들러를 활용할테니 여기까지 이해했다면 반 정도는 이해했다고 봅니다.
정리
Armeria는 HTTP/1.1에서 동작하는 Thrift를 HTTP/2 환경에서 서비스하거나 HTTP/2에서 동작하는 gRPC를 HTTP/1.1 환경에서 서비스 하는 등 매우 유연한 통신 방식을 구성할 수 있다는 장점을 갖고 있습니다. 이번엔 어떻게 gRPC를 HTTP/1.1에서 사용하는지 직접 알아보았는데요. 먼저 HTTP/2에서 어떻게 동작하는지 이해하고 그걸 HTTP/1.1의 chunked transfer encoding을 이용해 구현했다는 것을 확인했습니다. 직접 WireShark로 요청과 응답을 캡처해서 어떤 데이터가 오가는지 확인하고, 마지막으로 실제 Armeria 코드는 어떻게 구현되어있는지 알아봤습니다.
최근 Armeria 관련 블로그 글은 모두 코드에 기여하면서 했던 공부를 정리해서 썼습니다. 이 글은 평소와 다르게 순수하게 궁금한 내용을 찾아보고 알게 된 것을 정리했습니다. 이전부터 쓰고 싶었는데 너무 내용이 방대할 것 같아서 엄두를 못내고 있었습니다. 실제로 공부하는데 24시간, 글쓰는데 6시간 정도 소요한 대장정이었습니다. 😇 그래도 오랫동안 궁금했던 부분도 해소하고 Armeria의 중심 로직에 대해 많이 이해한 것 같아 남는게 더 많았던 투자였습니다. 특히 WireShark를 이번에 처음 써봤는데 직접 HTTP 전문을 뜯어보기 전에는 막연하게 어렵다고 생각했는데 의외로 쉽게 이해되었습니다. 진작 해볼걸 그랬다는 생각도 들었네요. 결론적으로 Armeria의 대단함을 다시 한 번 느꼈습니다. 다양한 통신 방식에 대한 이해를 쌓기 위한 공부 목적으로도 좋고 현실의 문제를 해결하기 위한 고성능 서버로도 좋습니다. 이 글을 읽으시는 분들도 Armeria의 개성적인 장점에 대해 공부하신 내용을 공유해주시면 큰 도움이 될 것 같습니다.